- Aprenda um idioma por 15 minutos ao dia e faça progressos rápidos.
- Retenha permanentemente vocabulário e expressões com o método de repetição inteligente SuperMemo, aclamado mundialmente.
- Tenha acesso a 25 idiomas e quase 300 cursos.
- Desenvolva suas habilidades de fala praticando conversas reais no MemoChat com tecnologia de IA.
- Use o aplicativo em qualquer número de dispositivos, online ou offline.
Que língua gostaria de aprender?
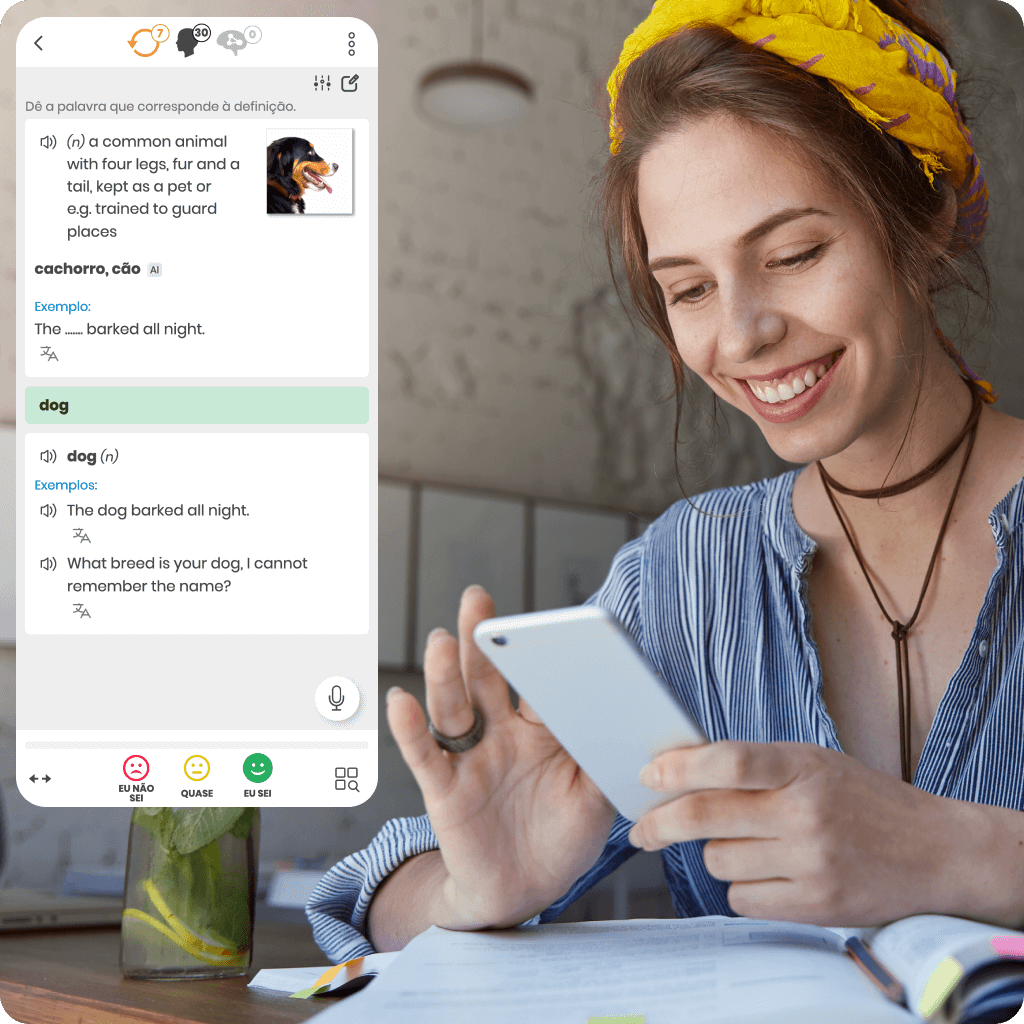



Fomos os primeiros a introduzir o sistema de repetição inteligente para apoiar o aprendizado online eficaz. Nossa pesquisa e desenvolvimento únicos nos tornam líderes nessa tecnologia.
Cada curso de idioma online que oferecemos é baseado em um algoritmo proprietário que determina com precisão o momento ideal para revisões. Isso garante que você aprenda mais rápido, de forma mais eficaz, e retenha o conhecimento por mais tempo.
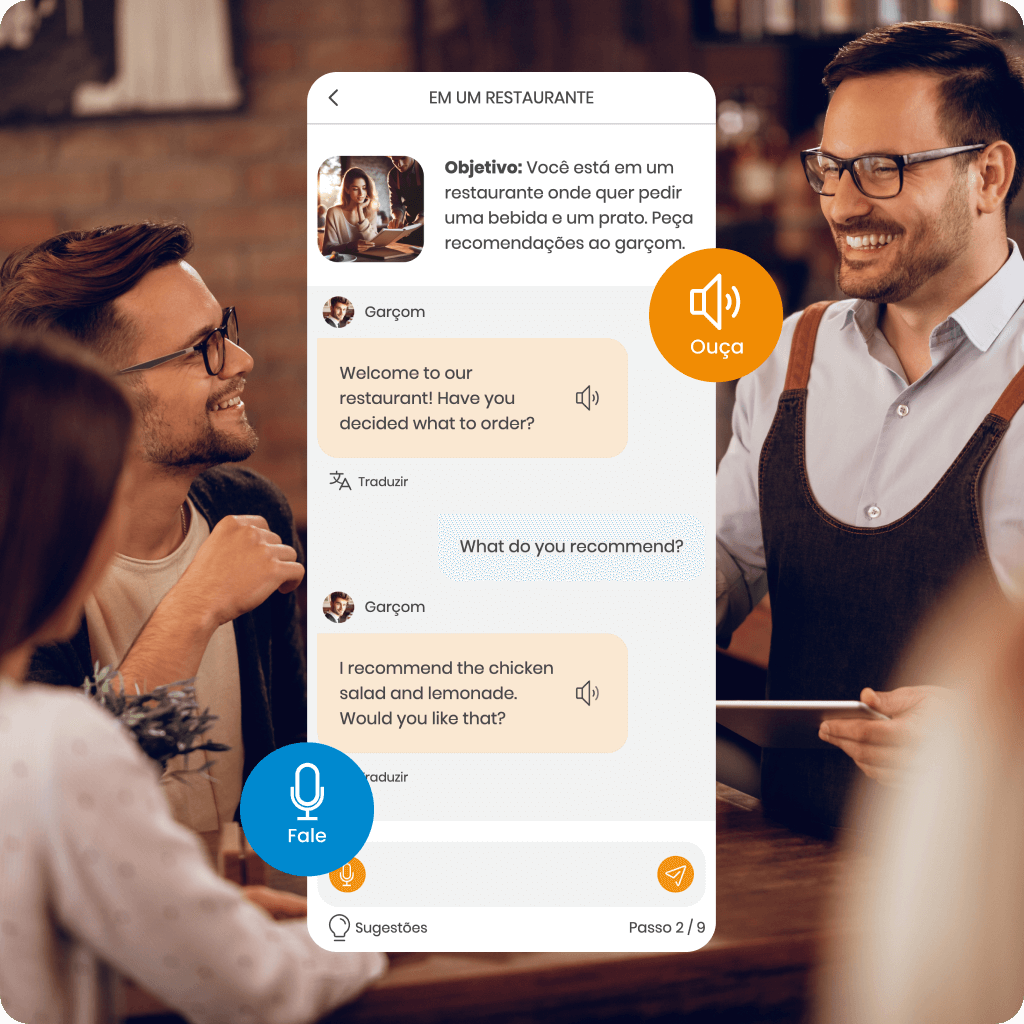
Descubra o MemoChat – diálogos interativos no SuperMemo impulsionados por IA, oferecendo uma variedade de tópicos de conversa e a capacidade de propor os seus próprios. O MemoChat fornece sugestões de respostas, traduções instantâneas e correções de erros, enquanto palavras recém-aprendidas podem ser facilmente adicionadas aos seus cursos, criando materiais de estudo personalizados.
Com a ajuda do Assistente de IA, você entenderá a gramática, traduzirá palavras desconhecidas e aprenderá a usá-las corretamente no contexto, acelerando significativamente seu progresso.
Além disso, o MemoTranslator traduz instantaneamente palavras e frases, que você também pode adicionar aos seus cursos para tornar seu aprendizado ainda mais eficaz.
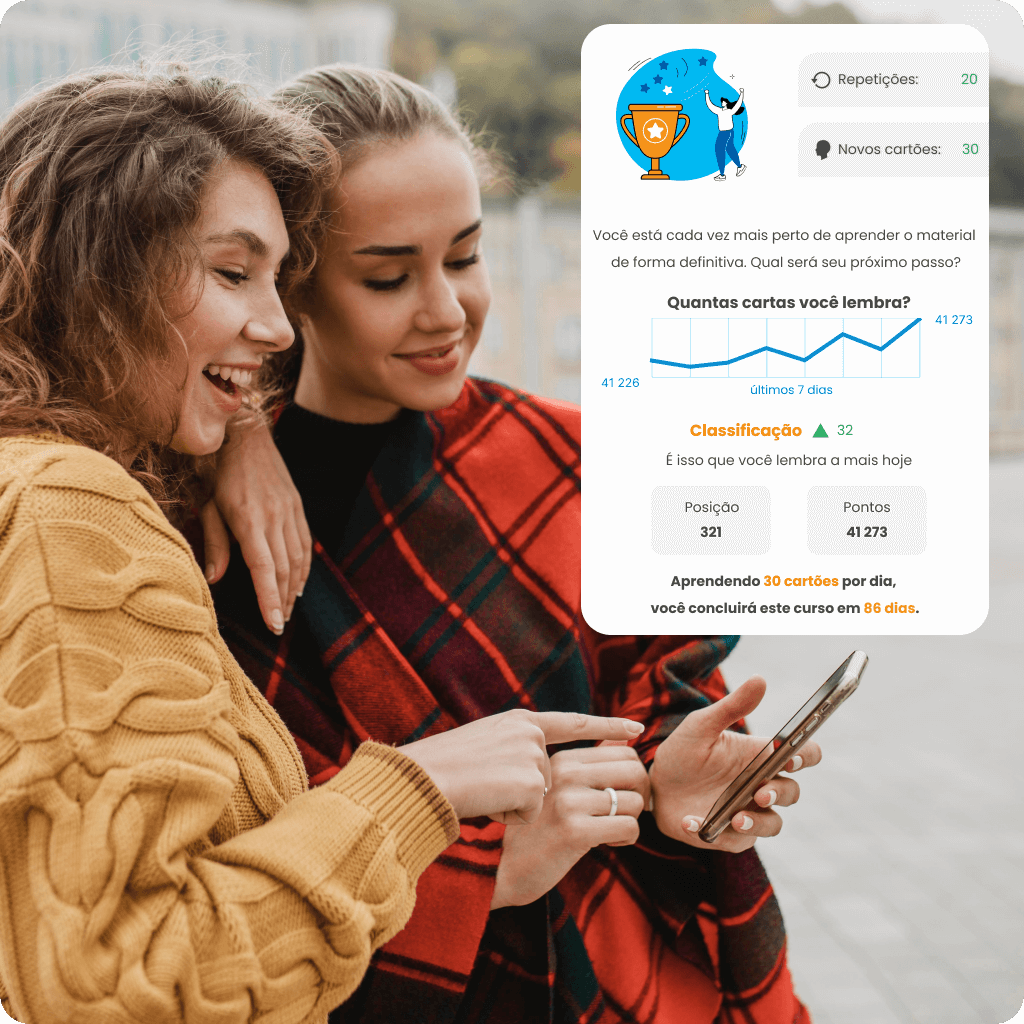
Ajuste o seu ritmo de aprendizagem de idiomas para atender às suas necessidades e ao tempo disponível com um plano de aprendizagem personalizado. Acompanhe seu progresso em tempo real com estatísticas, veja o quanto já dominou e confira seu ranking em relação a outros usuários no ranking. Escolha um curso que não apenas o motive a agir, mas também ajude você a alcançar seus objetivos de forma eficaz.

Explore uma variedade de cursos que desenvolvem vocabulário e gramática em cada nível de proficiência. Ganhe confiança ao falar com o recurso de reconhecimento de fala e diálogos interativos. Melhore suas habilidades de compreensão de leitura e aperfeiçoe sua ortografia.


Reimagine Education
Awards 2020
VencedorBETT
Awards 2020
FinalistaThe London Book Fair 2018
International Excellence Awards
FinalistaEducation Resources
Awards 2018
FinalistaGESS Education
Awards 2018
FinalistaBETT
Awards 2017
Finalista