- Вивчайте мову по 15 хвилин на день і досягайте швидкого прогресу.
- Назавжди запам’ятовуйте слова та вирази за допомогою всесвітньо визнаного методу інтелектуальних повторень SuperMemo.
- Отримайте доступ до 25 мов і майже 300 курсів.
- Розвивайте навички розмови, практикуючи реальні діалоги в MemoChat з технологією AI.
- Використовуйте додаток на будь-якій кількості пристроїв, онлайн або офлайн.
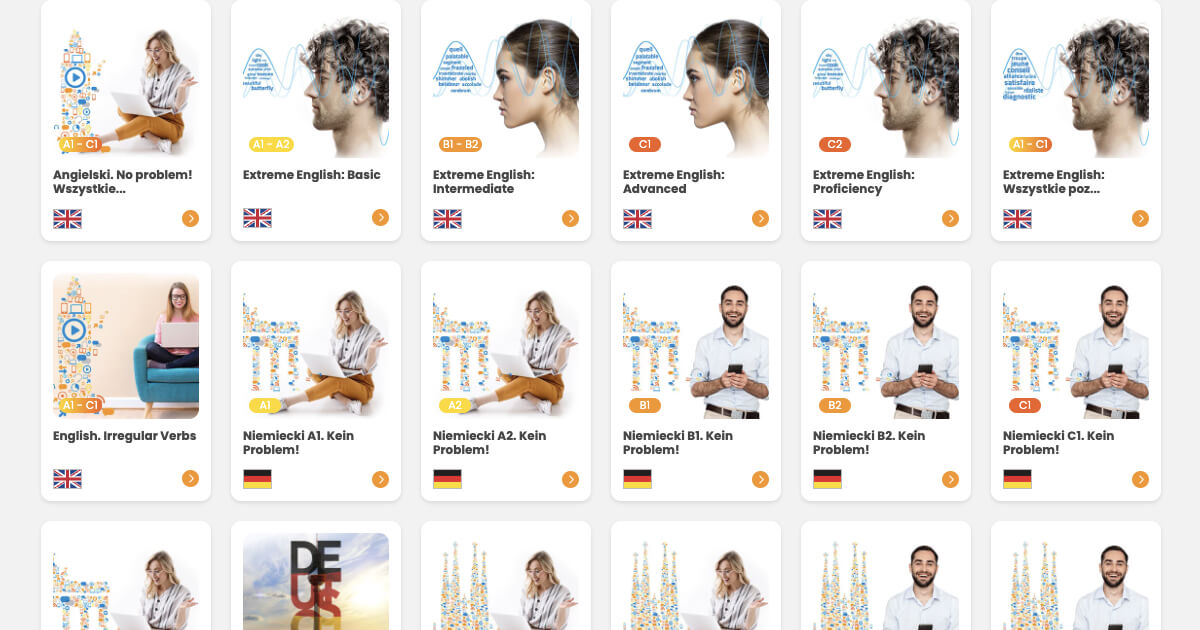
Яку мову ви хотіли б вивчити?
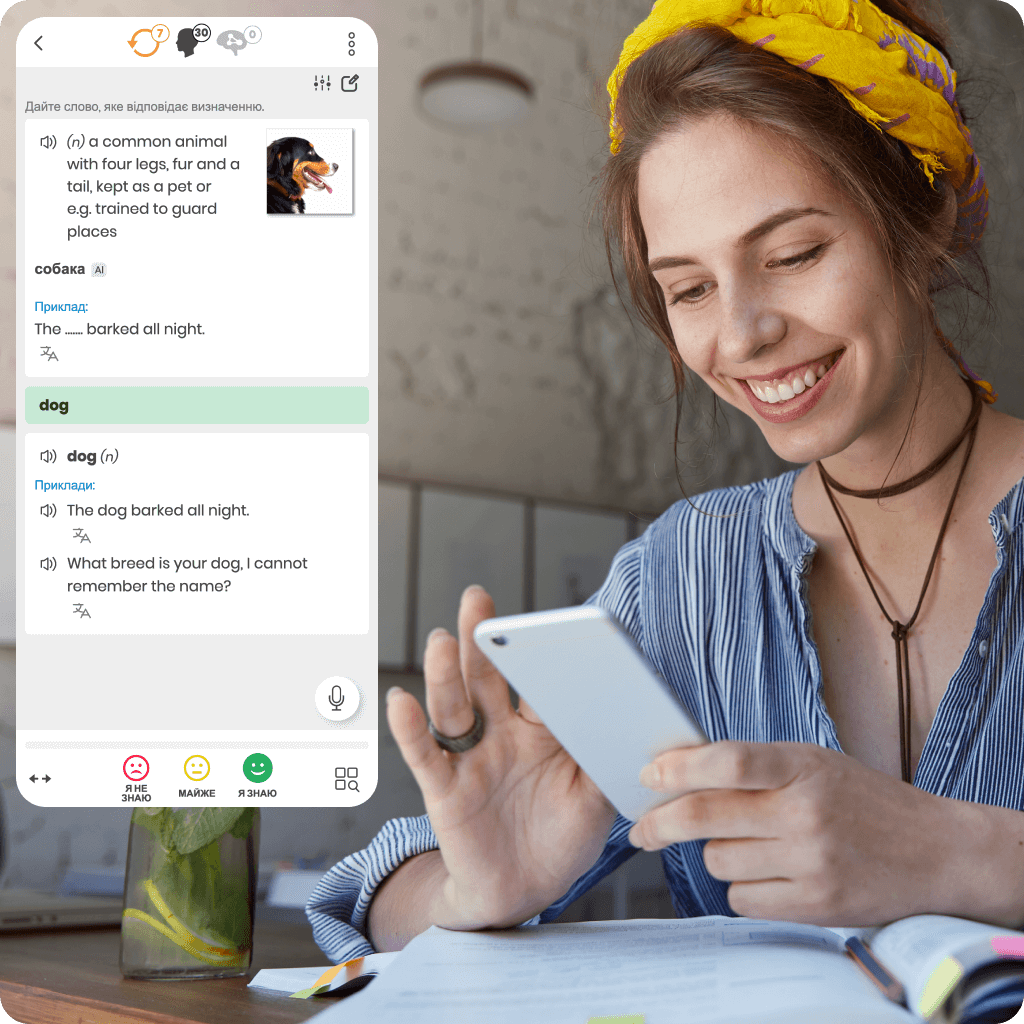



Ми першими впровадили систему інтелектуальних повторень для підтримки ефективного онлайн-навчання. Наші унікальні дослідження та розробки роблять нас лідерами в цій технології.
Кожен онлайн курс мови, який ми пропонуємо, заснований на власному алгоритмі, який точно визначає ідеальний момент для повторення. Це забезпечує швидше, ефективніше вивчення і довготривале збереження знань.
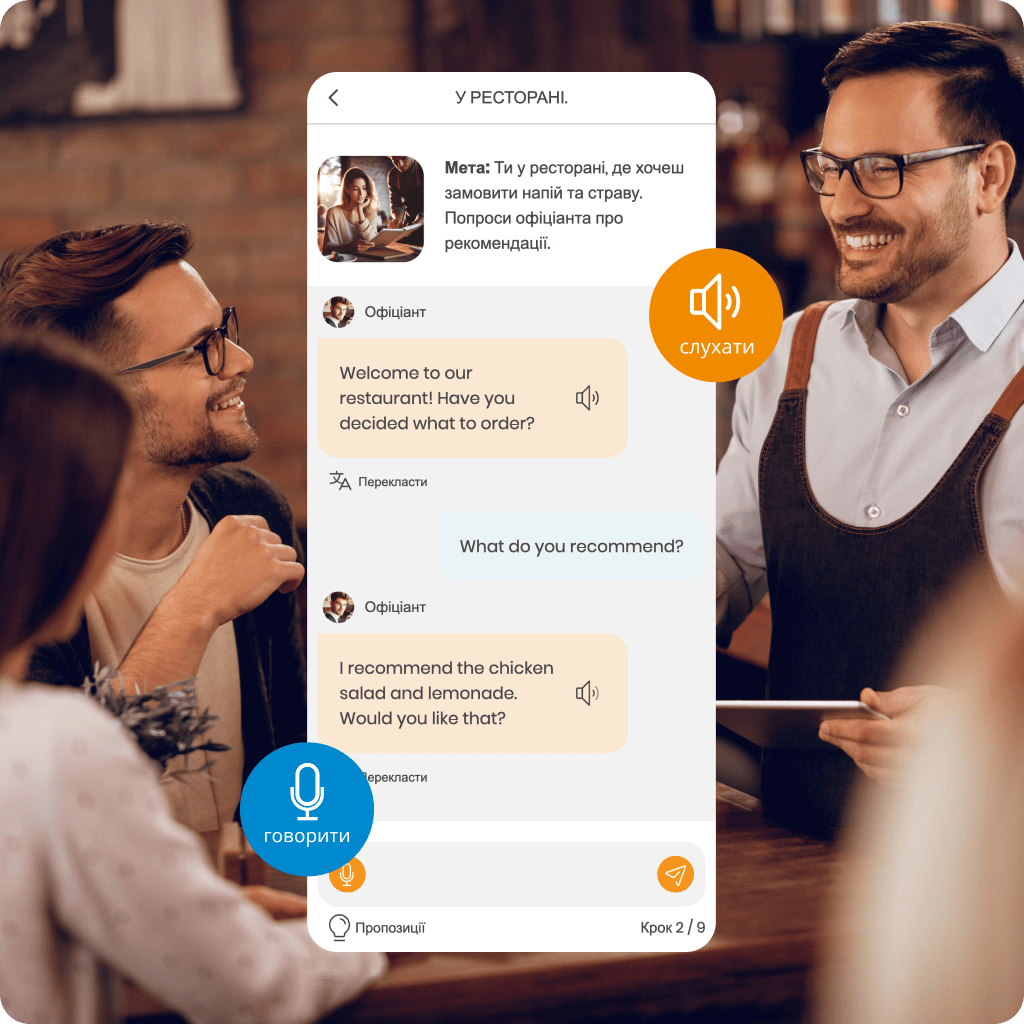
Відкрийте для себе MemoChat – інтерактивні діалоги в SuperMemo з підтримкою AI, які пропонують різноманітні теми для розмови та можливість пропонувати власні. MemoChat надає варіанти відповідей, миттєві переклади та виправлення помилок, а нові вивчені слова можна легко додати до своїх курсів, створюючи персоналізовані навчальні матеріали.
Завдяки AI Асистенту ви зможете зрозуміти граматику, перекладати незнайомі слова та навчитися правильно їх використовувати в контексті, що значно прискорить ваш прогрес.
Крім того, MemoTranslator миттєво перекладає слова та речення, які ви також можете додавати до своїх курсів, роблячи своє навчання ще більш ефективним.
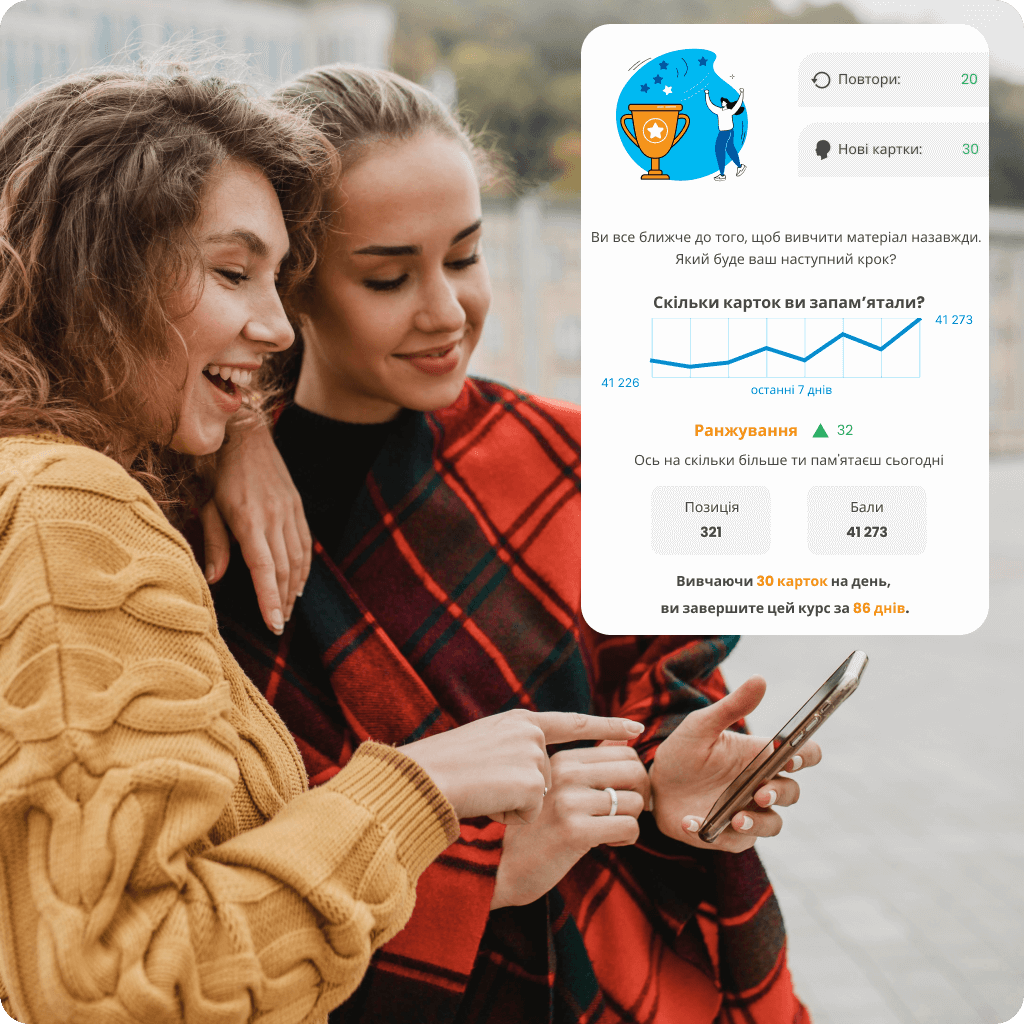
Налаштуйте темп вивчення мови відповідно до ваших потреб і вільного часу за допомогою персоналізованого плану навчання. Відстежуйте свій прогрес у реальному часі за допомогою статистики, переглядайте, скільки ви вже опанували, і дивіться, яке місце займаєте серед інших користувачів у рейтингу. Виберіть курс, який не лише спонукає вас до дії, але й допомагає ефективно досягати ваших цілей.

Відкрийте для себе різноманітні курси, які розвивають словниковий запас та граматику на кожному рівні володіння мовою. Наберіть впевненості в розмові завдяки функції розпізнавання мови та інтерактивним діалогам. Покращуйте навички розуміння прочитаного та удосконалюйте правопис.


Reimagine Education
Awards 2020
ПереможецьBETT
Awards 2020
ФіналістThe London Book Fair 2018
International Excellence Awards
ФіналістEducation Resources
Awards 2018
ФіналістGESS Education
Awards 2018
ФіналістBETT
Awards 2017
Фіналіст