- Lerne eine Sprache 15 Minuten am Tag und mache schnelle Fortschritte.
- Behalte Vokabeln und Ausdrücke dauerhaft im Gedächtnis dank der weltweit anerkannten Methode der intelligenten Wiederholungen von SuperMemo.
- Erhalte Zugang zum Lernen von 25 Sprachen und fast 300 Kursen.
- Entwickle deine Sprechfähigkeiten, indem du echte Gespräche im MemoChat mit KI-Technologie übst.
- Nutze die App auf beliebig vielen Geräten, online oder offline.
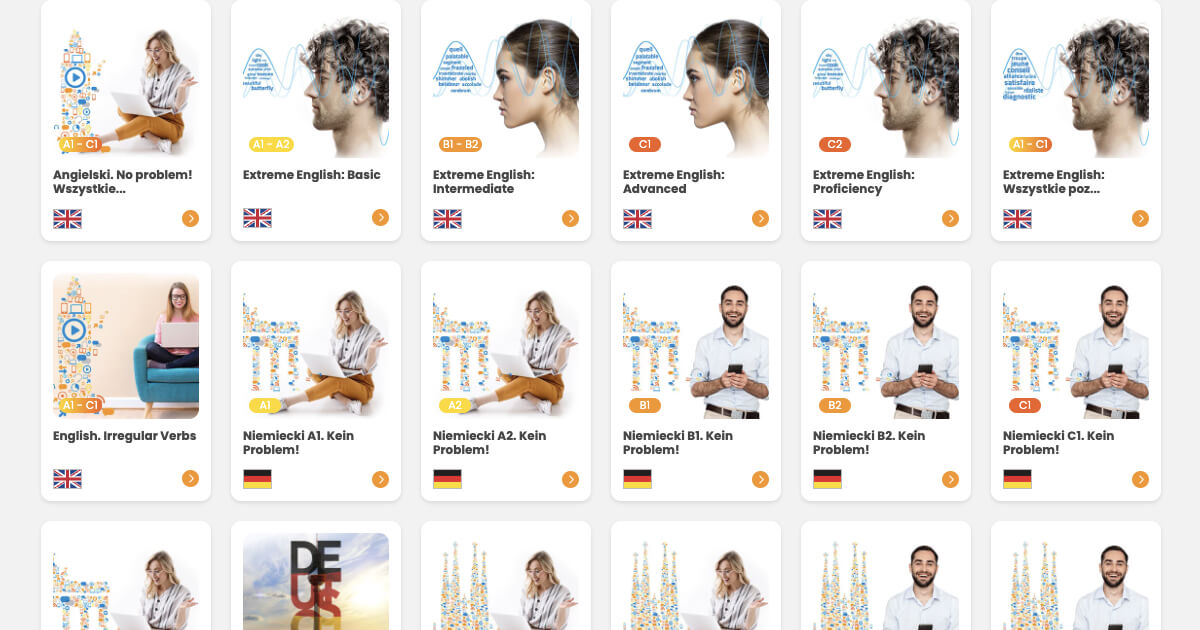
Welche Sprache würdest du gerne lernen?
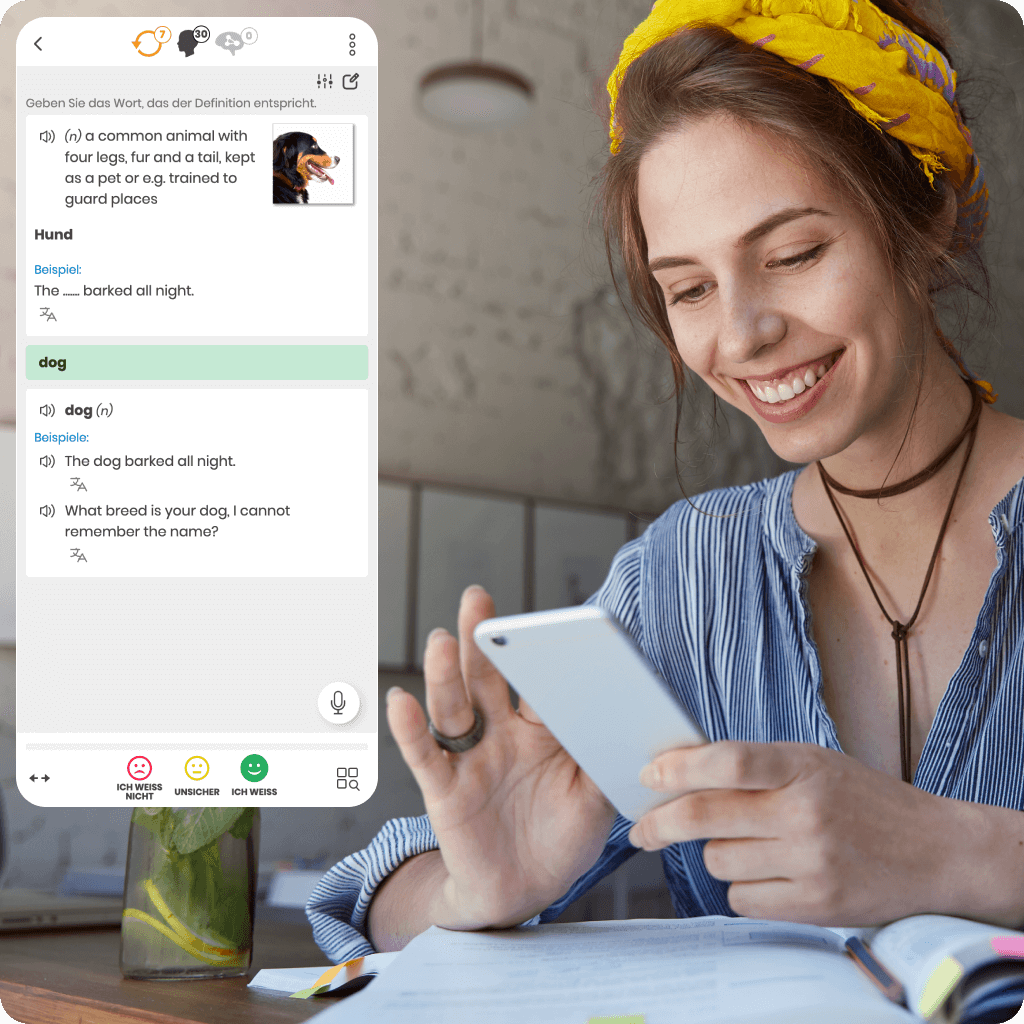



Wir waren die Ersten, die das intelligente Wiederholungssystem eingeführt haben, um effektives Online-Lernen zu unterstützen. Unsere einzigartigen Forschungsergebnisse und Entwicklungen machen uns zu führenden Experten in dieser Technologie.
Jeder Online-Sprachkurs, den wir anbieten, basiert auf einem proprietären Algorithmus, der den idealen Zeitpunkt für Wiederholungen präzise bestimmt. Das stellt sicher, dass du schneller, effektiver lernst und dein Wissen länger behältst.
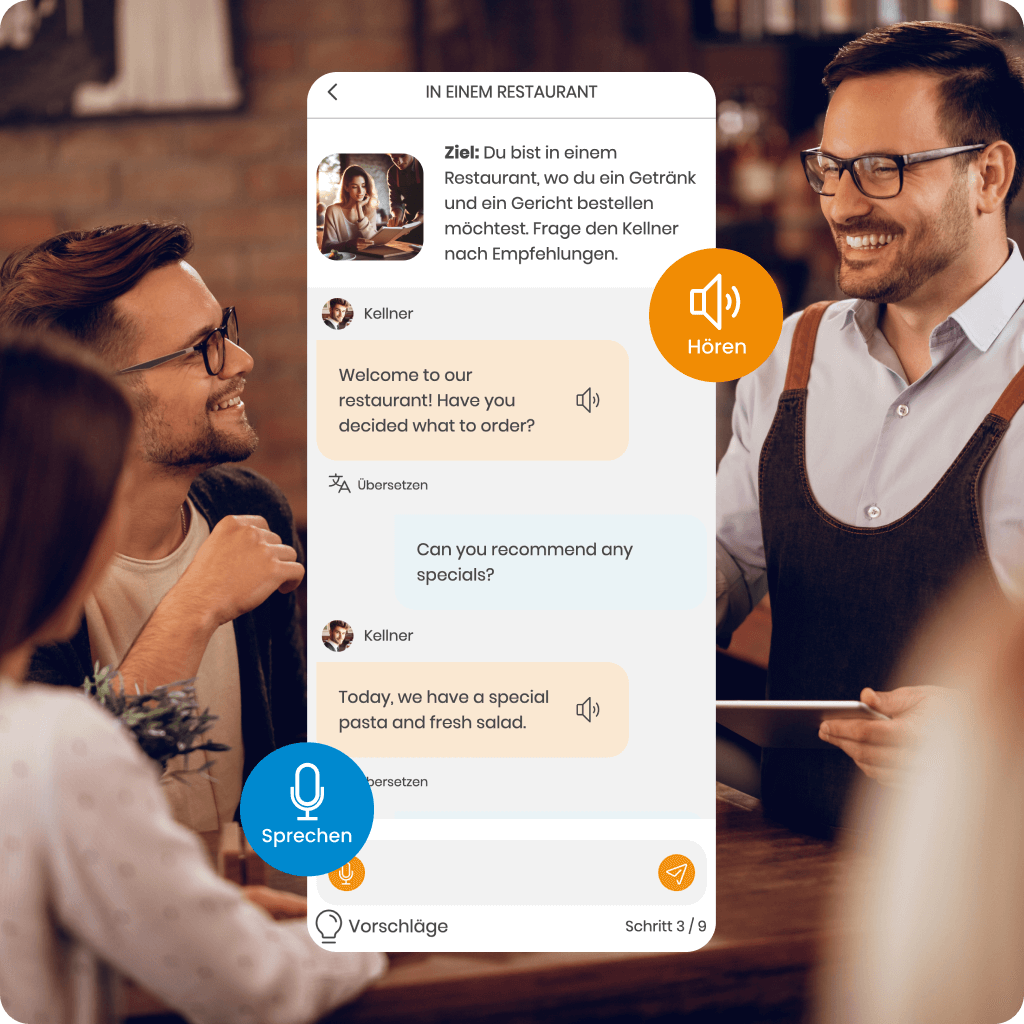
Entdecke MemoChat – interaktive Dialoge in SuperMemo, unterstützt von KI, mit einer Vielzahl von Gesprächsthemen und der Möglichkeit, eigene Vorschläge zu machen. MemoChat bietet Antwortvorschläge, sofortige Übersetzungen und Fehlerkorrekturen, während neu gelernte Wörter problemlos zu deinen Kursen hinzugefügt werden können, um personalisierte Lernmaterialien zu erstellen.
Mit der Hilfe des KI-Assistenten wirst du Grammatik verstehen, unbekannte Wörter übersetzen und lernen, sie korrekt im Kontext zu verwenden, was deinen Fortschritt erheblich beschleunigt.
Zusätzlich übersetzt der MemoTranslator Wörter und Sätze in Echtzeit, die du ebenfalls zu deinen Kursen hinzufügen kannst, um dein Lernen noch effektiver zu gestalten.
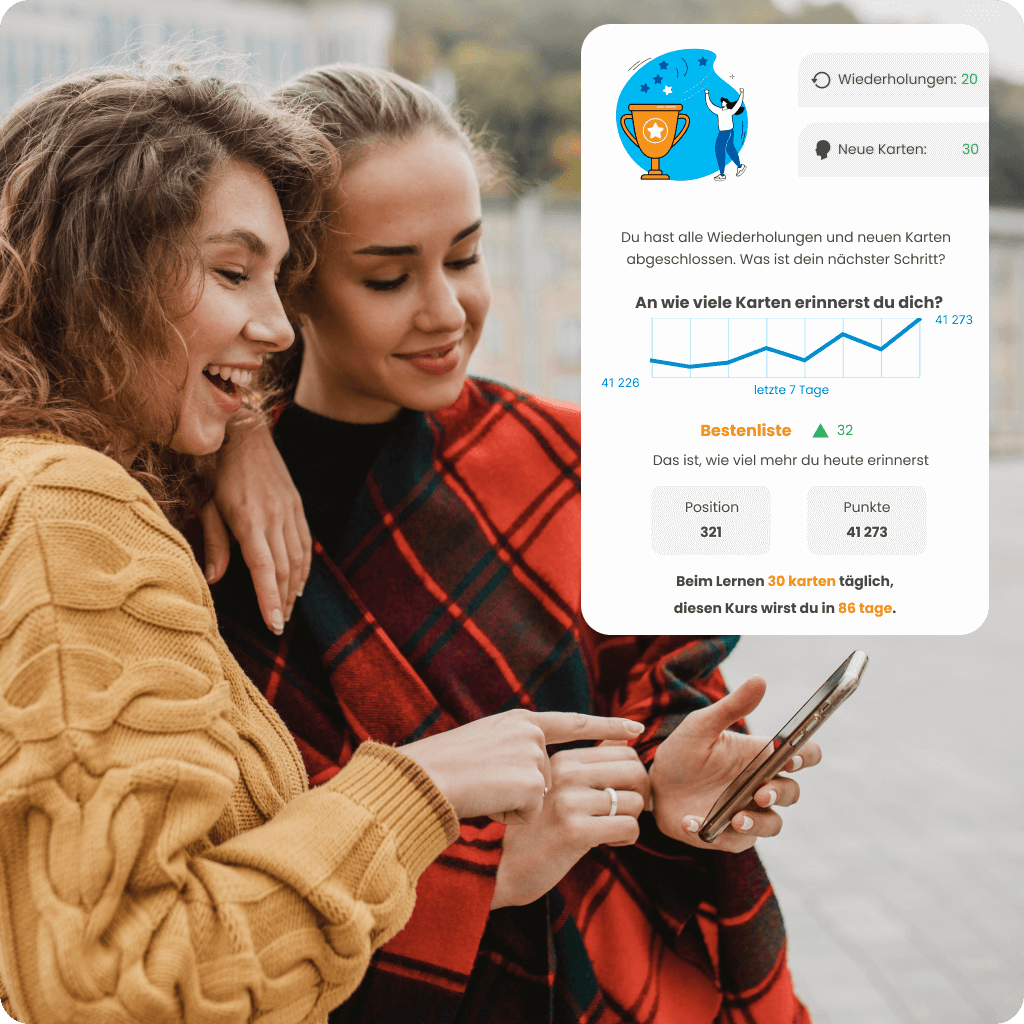
Passe dein Lerntempo an deine Bedürfnisse und verfügbare Zeit mit einem personalisierten Lernplan an. Verfolge deinen Fortschritt in Echtzeit mit Statistiken, überprüfe, wie viel du bereits gelernt hast, und sieh, wie du im Ranking im Vergleich zu anderen Nutzern abschneidest. Wähle einen Kurs, der dich nicht nur motiviert, sondern dir auch effektiv hilft, deine Ziele zu erreichen.

Entdecke eine Vielzahl von Kursen, die deinen Wortschatz und deine Grammatikkenntnisse auf jedem Sprachniveau verbessern. Gewinne Selbstvertrauen im Sprechen mit der Spracherkennungsfunktion und interaktiven Dialogen. Verbessere deine Lesekompetenz und perfektioniere deine Rechtschreibung.


Reimagine Education
Awards 2020
GewinnerBETT
Awards 2020
FinalistThe London Book Fair 2018
International Excellence Awards
FinalistEducation Resources
Awards 2018
FinalistGESS Education
Awards 2018
FinalistBETT
Awards 2017
Finalist